

La forma en que nos comunicamos digitalmente ha cambiado muchísimo. Hoy nos comunicamos hasta con stickers, pero ¿alguna vez te has preguntado cómo llegamos hasta aquí?
Seguramente navegando por internet te has encontrado con textos que muestran caracteres extraños como este: M�xico
Eso tiene un nombre: Mojibake. Así se le llama al fenómeno de ver caracteres raros cuando hay un error en la codificación del texto.
En este artículo te explico a detalle qué es la codificación, con ejemplos claros y sencillos.
Encodings
El encoding (o en español, codificación) es el proceso de transformar la información de una representación a otra siguiendo reglas específicas. En este contexto, nos enfocaremos en la codificación de caracteres: cómo se representan letras, números y símbolos en formato digital.
Me imagino que has escuchado que las computadoras solamente entienden números binarios: 0 y 1. Esto es cierto, pero imagina si tuviéramos que usar únicamente esos números para comunicarnos con ellas todos los días. Por eso, los investigadores desarrollaron sistemas que nos facilitan esta comunicación.
Te muestro un ejemplo con mi nombre. Sería impráctico tener que escribirlo usando solo ceros y unos.
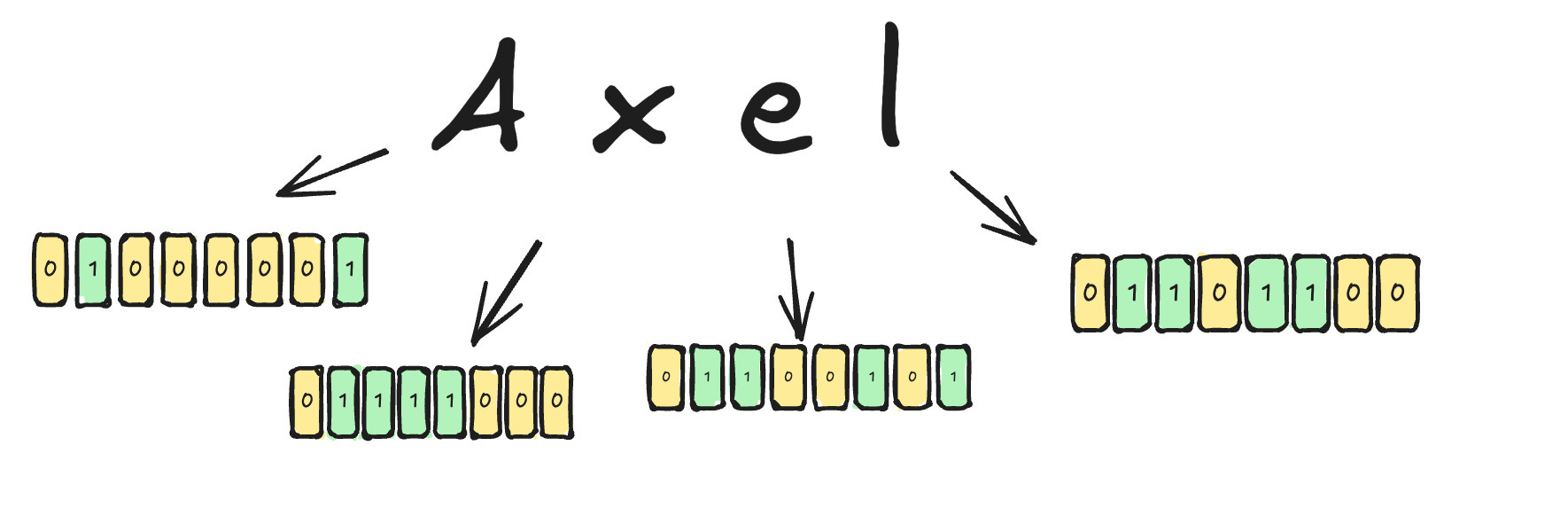
Son demasiados números, ¿cierto? ¿Cómo pasamos de letras a un montón de números?
Preguntas muy buenas, ser, joven Padawan
Retrocedamos un paso. Entendamos primero de dónde salieron esos números. Te presento a ASCII.
ASCII
ASCII son las siglas de American Standard Code for Information Interchange. Es un estándar que nos dice cómo deben representarse las letras como números para que las computadoras lo entiendan y nosotros también podamos entenderlo.
La primera versión de este estándar fue creada en 1963 y hasta hoy en día sigue siendo importante conocer que existe, porque es fácil de usar y los fabricantes de computadoras se encargan de que todas las PCs entiendan este formato.
Podemos encontrar la tabla ASCII que muestra cada letra del idioma inglés con un valor en decimal, hexadecimal y binario. Es por eso que pude transformar mi nombre a números binarios: porque cada letra cuenta con un valor que las computadoras pueden entender.
Te dejo los caracteres que usé:
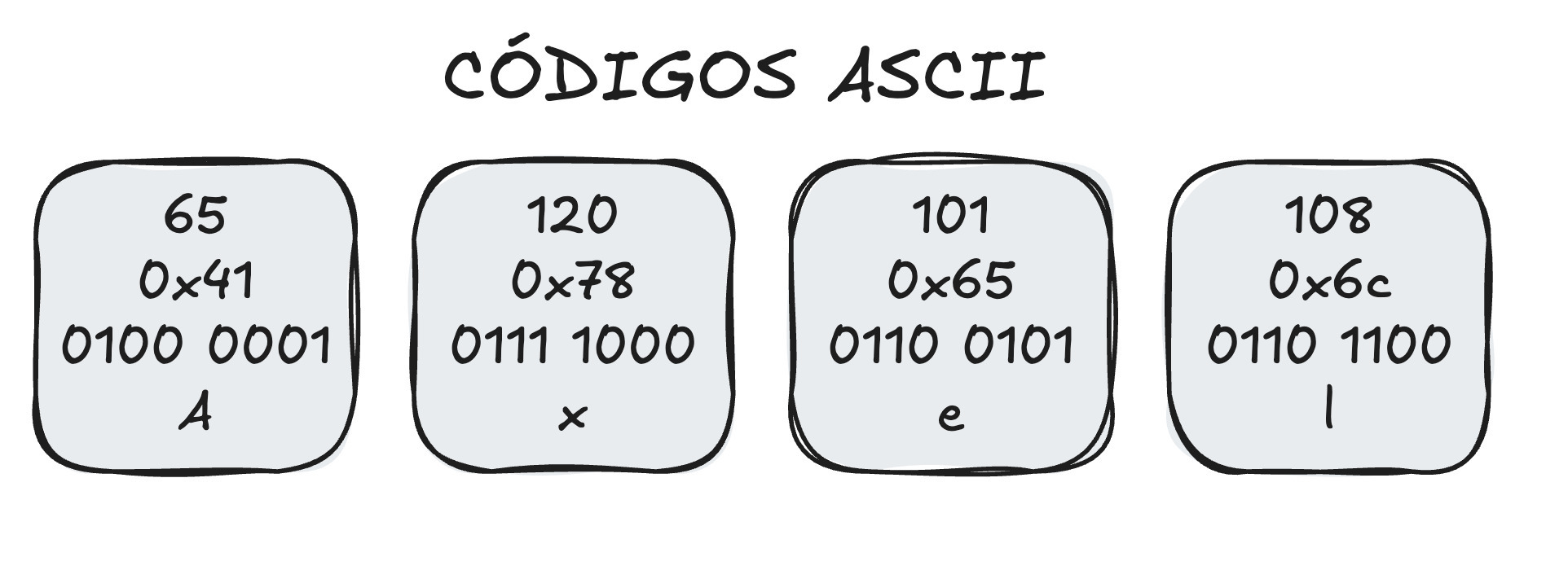
La codificación ASCII solo nos provee de 127 caracteres, lo que equivale a 7 bits (2^7). Esto es importante porque la computadora utiliza 1 byte (8 bits) para poder almacenar un carácter, es decir, que se está desperdiciando un bit. Y precisamente de eso se dieron cuenta los investigadores, así que después decidieron extender esta tabla de caracteres a 256. Ahora un carácter podía utilizar hasta 8 bits, o lo que es igual a 1 byte completo.
Esta expansión fue clave para que otros países con idiomas y alfabetos diferentes al inglés pudieran usar la codificación sin problemas de compatibilidad.
Pero aquí viene el detalle: 256 caracteres no son suficientes cuando tienes que representar chino, árabe, cirílico y todos los demás alfabetos del mundo. Cada fabricante empezó a inventar su propia solución, y ahí es donde empezó el problema de M├®xico que viste arriba. La solución a este caos fue Unicode.
Unicode
Unicode se creó en los años 80 y se convirtió en un estándar hoy en día que define más de 1.1 millones de caracteres. Este estándar asigna a cada carácter un código que después, con ayuda de un encoding, se transforma a bits (lo que realmente la computadora entiende). Y no solamente se trata de letras: los emojis también están dentro de Unicode y por eso podemos utilizarlos en cualquier idioma.
La idea principal de Unicode es evitar que cada fabricante de hardware cree su propio encoding incompatible con los demás. Así, un fabricante en Europa que usa caracteres distintos al inglés puede compartir información con alguien en Asia o en América, evitando el caos de M├®xico que vimos antes.
Los códigos Unicode están definidos con un formato hexadecimal y se ven así:
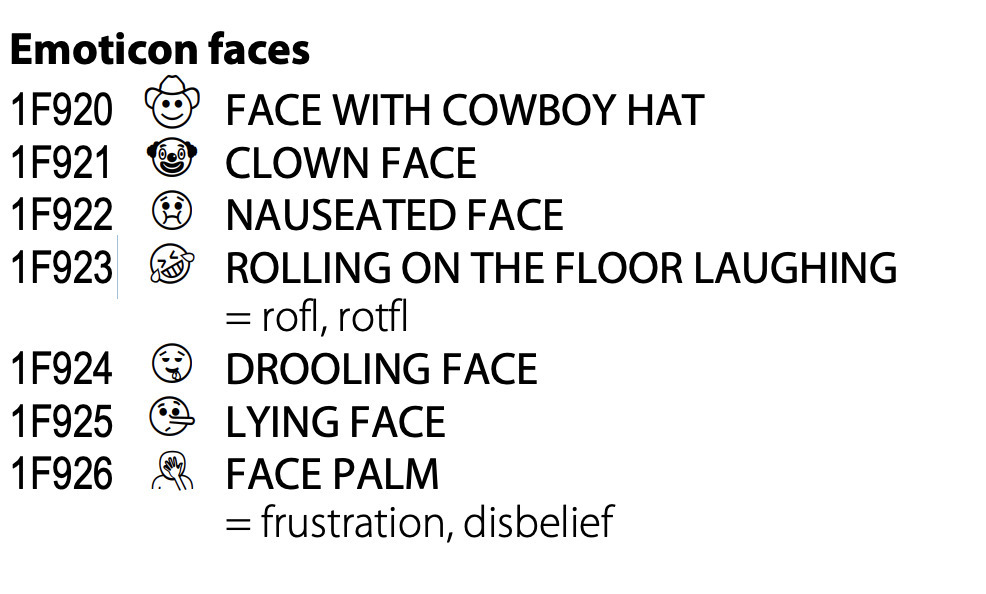
Si ves esto y no sabes qué es hexadecimal, te dejo un link a un artículo: https://en.wikipedia.org/wiki/Hexadecimal
Listo. Ya conocemos Unicode y por qué es importante, pero esto solo nos da una pequeña porción del panorama completo. Recuerda que la computadora solo entiende bits, entonces, ¿cómo pasamos de estos códigos hexadecimales a bits? Aquí es donde entra UTF-8 🙌🏻
UTF-8 👾
UTF-8 es un encoding creado por el consorcio Unicode (los mismos que crearon el estándar Unicode) y se encarga de transformar los códigos hexadecimales a bits que la computadora pueda entender.
Algo muy inteligente de UTF-8 es que fue diseñado desde el inicio para ser compatible con ASCII. Los primeros 128 códigos tienen una traducción idéntica, es decir, se conservan los códigos ASCII. Por ejemplo, la letra A en ASCII es 65 (en decimal) y en UTF-8 también es 65.
Esto permitió que programas que ya usaban ASCII funcionaran automáticamente con UTF-8, lo que mejoró la adopción y ahora UTF-8 sea el encoding más popular en la web.
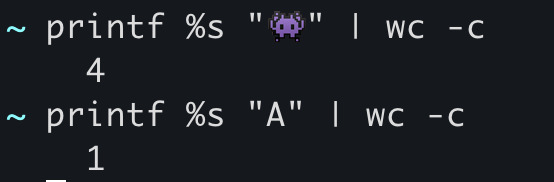
UTF-8 utiliza una transformación dinámica a bits: caracteres simples ocupan solo 1 byte, mientras que caracteres más complejos —con múltiples formas, diacríticos, etc.— pueden ocupar hasta 4 bytes.
Por ejemplo, este emoji 👾 ocupa 4 bytes completos, mientras que la letra A solo necesita 1 byte:
Charset y Encoding
Perfecto. Ya sabes cómo funcionan ASCII, Unicode y UTF-8. Pero hay una distinción importante que te ayudará a entender todo el panorama: charset vs encoding.
Cuando trabajas con bases de datos o creas un documento HTML, seguro has visto una etiqueta o configuración llamada charset. Esto se refiere al catálogo de caracteres que puedes usar en ese documento y que se mostrarán correctamente en pantalla. Es decir, qué caracteres están “permitidos” o “disponibles”.
El encoding, por otro lado, es la forma en que esos caracteres se transforman a bits para ser almacenados o transmitidos.
¿Por qué importa?
Si no trabajas con el mismo charset en documentos compartidos, terminas con el problema que vimos antes: caracteres rotos, símbolos raros y texto ilegible.
Ejemplo práctico
Imagina que creas un archivo de texto con este contenido:
México
Creamos el archivo en nuestra computadora y verificamos su encoding con el comando file:
~ echo "México" > test.txt
~ file -I test.txt
test.txt: text/plain; charset=utf-8
Perfecto, está en UTF-8. Ahora intentemos convertirlo a un encoding que no soporte acentos, como ISO-8859-10 (diseñado para idiomas nórdicos: sueco, noruego, danés).
Usamos la herramienta iconv para transformar el encoding:
~ iconv -f UTF-8 -t ISO-8859-10 test.txt > converted.txt
~ cat converted.txt
M�xico
¿Qué pasó? 😳 El archivo ahora contiene caracteres raros donde debería estar la “é”. La terminal no puede mostrarlo bien, pero un editor de texto sí revela el problema:
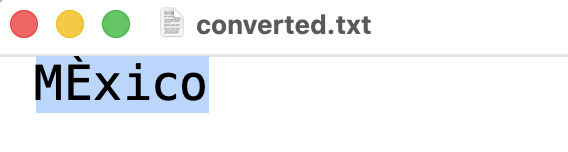
Nuestro archivo original estaba en UTF-8, donde la “é” tiene un código específico. Al convertirlo en ISO-8859-10, iconv intentó encontrar un equivalente... pero no es lo mismo, por eso se ve raro.
Ahora, si intentamos convertirlo a ASCII (que en teoría es compatible con UTF-8), vemos que directamente no puede manejar el acento porque en el charset ASCII no existen letras con acento como sí existen en Unicode:
~ iconv -f UTF-8 -t ASCII -c test.txt > converted.txt
iconv: warning: invalid characters: 1
~ cat converted.txt
Mxico
Incluso si abres el editor, verás que no se logró transformar la segunda letra:
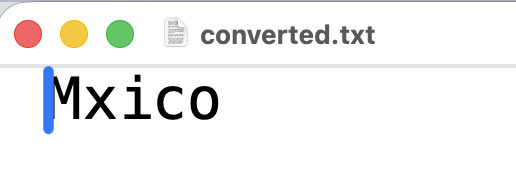
La letra “é” simplemente desapareció. Para verificar que el nuevo archivo tiene otro encoding, ejecutamos:
~ file -I converted.txt
converted.txt: text/plain; charset=us-ascii
Ahí está: ahora es us-ascii.
Ejemplo en programación
Listo. Ya entendemos la diferencia entre charset y encoding. ¿Pero cómo nos ayuda esto al programar?
Imagina este problema:
"Valida si una cadena de texto contiene únicamente caracteres A-Z y dígitos 0-9"
Para resolverlo, vamos a asumir que la cadena de texto es pequeña y trabajaremos con los códigos ASCII:
function containsOnlyLettersAndNumbers(s) {
for (let i = 0; i < s.length; i++) {
let char = s.charCodeAt(i);
console.log(`Evaluating s[${i}]= ${s[i]} charcode=${char}`);
if (char < 48 || char > 122) return false;
if (char > 57 && char < 65) return false;
if (char > 90 && char < 97) return false;
}
return true;
}
console.log(containsOnlyLettersAndNumbers("AUDID3222")) // TRUE
console.log(containsOnlyLettersAndNumbers("D444E##RUURUJ")) // FALSE
console.log(containsOnlyLettersAndNumbers("asbueu3$")) // FALSE
console.log(containsOnlyLettersAndNumbers("asbueu3")) // TRUE
Este código puedes probarlo con herramientas como RunJS o de una forma visual con un editor que te muestra el paso a paso que tiene soporte para JavaScript: PythonTutor
Conclusión
Y así llegamos al final. En este artículo vimos cómo funcionan los encodings, por qué un emoji puede ocupar 4 bytes y ejemplos prácticos de transformaciones entre charsets.
Reacciona:
❤️ Sí, ya lo conocías
🔥 Si te sorprendió algo
💬 Y cuéntame qué fue lo que más te llamó la atención
Si crees que me faltó algo importante, déjamelo en los comentarios. Te estaré leyendo. 👇
Comentarios